Serija: Podatki, pripravljeni na umetno inteligenco — 2. del
V prvem članku v seriji smo postavili jasno diagnozo: uvajanje umetne inteligence običajno ne spodleti zaradi šibkih modelov. Spodleti zato, ker so odgovori nezanesljivi, neizsledljivi in preprosto nevarni za resno poslovno odločanje.
To nas pripelje do naslednjega vprašanja: kaj v vsakodnevni realnosti pomeni, da so podatki pripravljeni na umetno inteligenco? Ne v teoriji. Ampak v organizacijah, kjer so podatki razmetani po različnih sistemih, oddelkih in orodjih.
Eno od ključnih sporočil predavanja Lukasa Zimmermanna (Strategy) na našem decembrskem dogodku AI Success Starts with AI-Ready Data je bilo, da »AI-ready« podatki niso le očiščene tabele ali selitev v oblak. Gre za to, da umetni inteligenci (in ljudem) podamo manjkajoči poslovni kontekst, in sicer dosledno, varno in v čim večjem obsegu.
In prav na tej točki semantični sloj spreminja pravila igre.
Blog serija: Podatki, pripravljeni na umetno inteligenco
1: Kaj pomeni “na AI pripravljeni podatki”?
2: Enoten vir resnice: Zakaj je semantični sloj hrbtenica zanesljive poslovne umetne inteligence
3: Zakaj infrastruktura odloča o uspehu poslovne umetne inteligence
Izzivi pri umetni inteligenci, s katerimi se še vedno sooča večina organizacij
Večina podjetij nima enovitega sistema. Delujejo kot krpanka:
- Številni viri (ERP, CRM, finance, Excel),
- Številna analitična orodja (Power BI, Qlik, Tableau, notebooks),
- Številne ekipe ali oddelki, ki vzporedno in vsak po svoje definirajo metrike.
Rezultat je tisti znani »strukturirani kaos«, ko so nadzorne plošče sicer videti vrhunsko, a se podatki med seboj ne ujemajo. Poročila se ne skladajo, definicije ključnih metrik pa skozi čas potihem odtavajo vsaka v svojo smer.

V takšnem okolju umetna inteligenca nereda ne odpravi, pač pa ga le še poslabša.
Ko generativno umetno inteligenco povežete z razdrobljenimi in nedoslednimi podatki, ne tvegate le napačnih odgovorov. Tvegate:
- samozavestne napačne odgovore (najbolj nevarna vrsta!),
- nepojasnjene rezultate (brez možnosti preverjanja vira),
- nevarne odgovore (ko UI v praksi obide pravila zasebnosti in dostopa).
Podatki, pripravljeni na umetno inteligenco, se torej ne ustavijo pri urejenih podatkovnih tokovih in ustreznem dostopu. Zahtevajo tudi nadzorovan sloj, kjer poslovni pomen in pravila ostajajo dosledni v vseh poročilih, nadzornih ploščah in primerih uporabe UI.
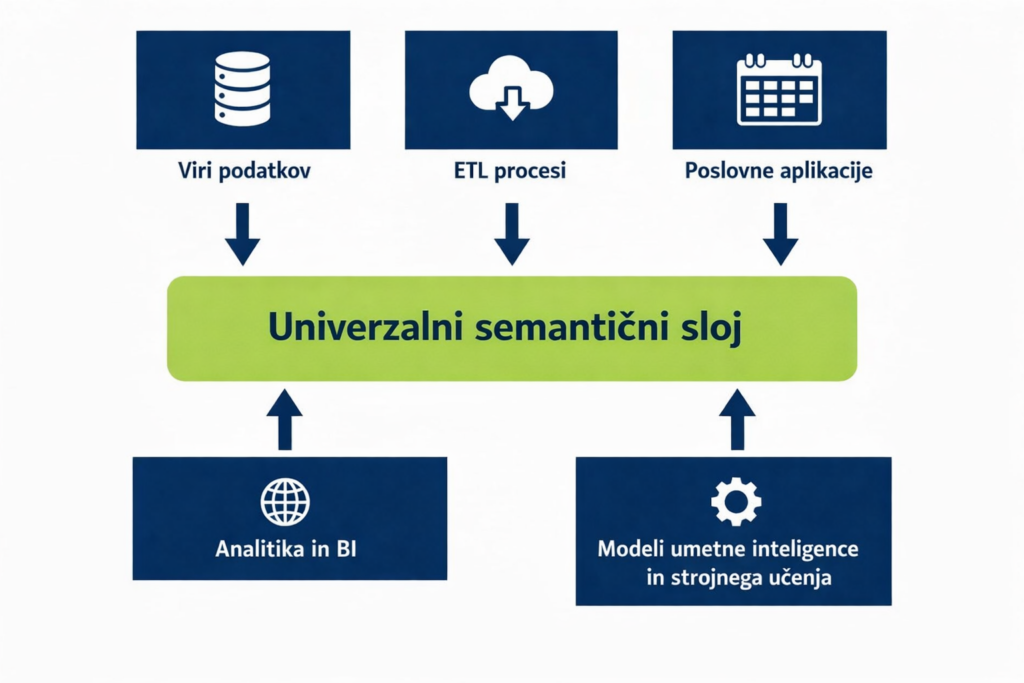
Kaj je vloga semantičnega sloja?
Semantični sloj je najbolje razumeti kot prevajalca in nadzornika med vašimi surovimi podatki in orodji (ali umetno inteligenco), ki jih uporabljajo.
V praksi dela šest stvari:
- Tehnično kodo prevaja v poslovni jezik:
Preslika tabele, relacije in stolpce v konceptre, ki jih uporabnik pozna (prihodek, stranka, izdelek, regija, marža), z definicijami, ki ne dopuščajo interpretacij. - Ustvari enoten vir resnice za metrike:
Če je »prihodek« definiran enkrat z vsemi vključitvami in izjemami, vsa orodja in vsi uporabniki delajo z isto definicijo. - Omogoča univerzalen dostop v vseh orodjih:
Namesto da bi vsako orodje gradilo svojo logiko, lahko več orodij uporablja iste semantične definicije (BI orodja, Excel, Python/R in vse pogosteje vmesniki, ki jih poganja umetna inteligenca). - Centralno upravljanje in varnost:
Stroga pravila glede dostopa do informacij veljajo tudi, ko se v procese vključi generativna UI. - Izboljša zmogljivost in predvidljivost stroškov:
Manj podvajanja pomeni hitrejše delovanje in manj “presenečenj” na računu za oblak. - Zmanjšuje odvisnost od ponudnikov (lock-in) in povečuje agilnost:
Tehnologije se menjajo, vaša poslovna logika v semantičnem sloju pa ostaja stabilna.
“Saj že imamo ETL in podatkovno skladišče, mar to ni dovolj?”
ETL/ELT procesi in podatkovna skladišča so bistveni. Poskrbijo, da so podatki na voljo, strukturirani in prečiščeni.
Vendar pogosto ne rešujejo naslednjih izzivov:
- Poslovne definicije so razpršene na različnih mestih: Ena različica izračuna morda obstaja v Power BI, druga v Excelu, tretja pa v SQL.
- Varnostna pravila se izvajajo nedosledno: Dostop do posameznih podatkov je lahko v enem orodju nastavljen drugače kot v drugem, pri ad-hoc izvozih podatkov pa se pogosto popolnoma zaobide.
- Umetna inteligenca potrebuje dodatni kontekst, ki ga v shemi tabel ni: Generativna UI ne potrebuje le »stolpcev«. Potrebuje dodatne informacije glede tega, kaj je uradno, čemu se zaupa in do katerih podatkov je omejen dostop.
Semantični sloj ne nadomešča procesov ETL. Postavi se nad njih in odgovarja na vprašanji: »Kaj ti podatki pomenijo za naše poslovanje?« in »Kako jih varno uporabiti?«
Zakaj je semantični sloj v dobi GenAI še pomembnejši?
Pri klasični analitiki (BI) uporabnik zgradi nadzorno ploščo, se nauči orodja in običajno sledi procesu upravljanja. Pri generativni UI se interakcija spremeni:
- Uporabniki postavljajo vprašanja v naravnem jeziku,
- Orodja dinamično generirajo poizvedbe,
- Rezultati so lahko videti verodostojni, tudi ko je logika napačna.
Semantični sloj pomaga generativni UI na dva ključna načina:
- Natančnost s pomočjo konteksta:
Če so poslovne definicije in razmerja centralno modelirani, ima UI stabilno strukturo za sklepanje. - Zaupanje s pomočjo upravljanja:
UI ne more “po nesreči” razkriti omejenih podatkov ali si sproti izmišljati novih definicij ključnih kazalnikov (KPI).
Obstaja ogromen prepad med uporabo umetne inteligence, ki le niza podatke, in odločitvijo, da ji brez pomislekov zaupate sprejemanje ključnih odločitev.
Praktična pot do urejenih podatkov
Priporočamo postopen proces, korak za korakom.
- Začnite z metrikami, ki povzročajo največ trenj:
Izberite področje, kjer so nesoglasja “draga” (npr. prihodki, marža, dobičkonosnost strank, metrike ESG ali regulativno poročanje). - Določite in potrdite poslovne definicije:
Definicije naj bodo jasne, dokumentirane in v lasti odgovornih oseb (finance/kontroling + IT + lastniki podatkov). - Modelirajte definicije enkrat in jih uporabite povsod: Zgradite semantični model, ki ga orodja lahko dosledno uporabljajo, namesto vsakokratnega oblikovanja logike za vsako nadzorno ploščo posebej.
- Nadzor nad dostopom do podatkov:
Poskrbite, da upravljanja podatkov ni mogoče zaobiti z novimi vmesniki. - Pilotni projekt z resničnimi uporabniki:
Uspeha ne predstavlja »delujoča demonstracija«, temveč manj usklajevanj in hitrejše odločitve na dolgi rok. - Širite po področjih:
Ne uvajajte orodja za orodjem, ampak pokrivajte posamezna vsebinska področja.
Zaključek: umetna inteligenca potrebuje kontekst, ne le podatkov
Podatki, pripravljeni na umetno inteligenco, ne pomenijo le urejenih tokov in sodobnih platform. Gre predvsem za skupen poslovni pomen in set izvedljivih pravil.
Semantični sloj je eden najučinkovitejših načinov za vzpostavitev teh temeljev. Poskrbi namreč, da so metrike dosledne, upravljanje praktično, končni rezultati pa veliko bolj zanesljivi, saj modelu ni več treba ugibati, kaj pomenijo vaši poslovni izrazi.
Naslednji koraki
Če vaša organizacija že eksperimentira s pametnimi pomočniki ali z AI podprto analitiko, a se hkrati še vedno bori z neskladnimi KPI-ji in razpršenimi definicijami, je to jasen opozorilni znak. To običajno pomeni, da vaši poslovni pomeni niso centralizirani.
CRMT pomaga organizacijam zasnovati okolja, pripravljena na umetno inteligenco, z usklajevanjem kakovosti podatkov, semantične doslednosti in ustrezne arhitekture orodij.
Vas zanima, kako bi se to obneslo v vašem podjetju? Stopite v stik z našo ekipo.
Sorodno branje
Kaj pomeni "na AI pripravljeni podatki"?
Umetna inteligenca je danes vseprisotna. Skoraj vsak teden se pojavljajo novi kopiloti, asistenti, agenti in obljube avtomatizacije. V praksi pa se številne or...
VečKako univerzalni inteligentni sloj preoblikuje poslovno poročanje
Učinkovito poročanje temelji na pravočasnih, točnih in konsistentnih podatkih. V praksi pa številna podjetja še vedno uporabljajo zastarele rešitve in Ex...
Več